

RS-YOLOv8: A Real-Time Road Segmentation Framework for Autonomous Driving Assistant Systems Using YOLOv8 and Automated Annotation
Author: Waqas Javaid
Abstract
The advancement of Autonomous Driving Assistant Systems (ADAS) is critically dependent on the ability to accurately and efficiently perceive the driving environment, with road segmentation being a foundational task. This project presents RS-YOLOv8, an innovative framework designed to deliver high-performance, real-time road segmentation. Building upon the foundational RS-ADAS project, RS-YOLOv8 integrates the state-of-the-art YOLOv8 object detection model with a novel automated annotation pipeline. This pipeline leverages the Segment Anything Model (SAM) to generate precise segmentation masks from YOLOv8’s bounding box detections, thereby creating a high-quality dataset without extensive manual labeling. The resulting YOLOv8 segmentation model is trained on this dataset to perform pixel-level road segmentation. Experimental results demonstrate that the model achieves a mean Average Precision (mAP@0.5) of 0.856 for bounding box detection and 0.848 for instance segmentation, while maintaining the low inference time requisite for real-time ADAS applications. The project successfully establishes a streamlined workflow from data collection to deployment, significantly reducing manual annotation overhead and enhancing the practicality of developing robust vision models for autonomous navigation.
Keywords: Autonomous Driving, ADAS, Road Segmentation, YOLOv8, Instance Segmentation, Automated Annotation, Real-Time Inference, Deep Learning.
Introduction
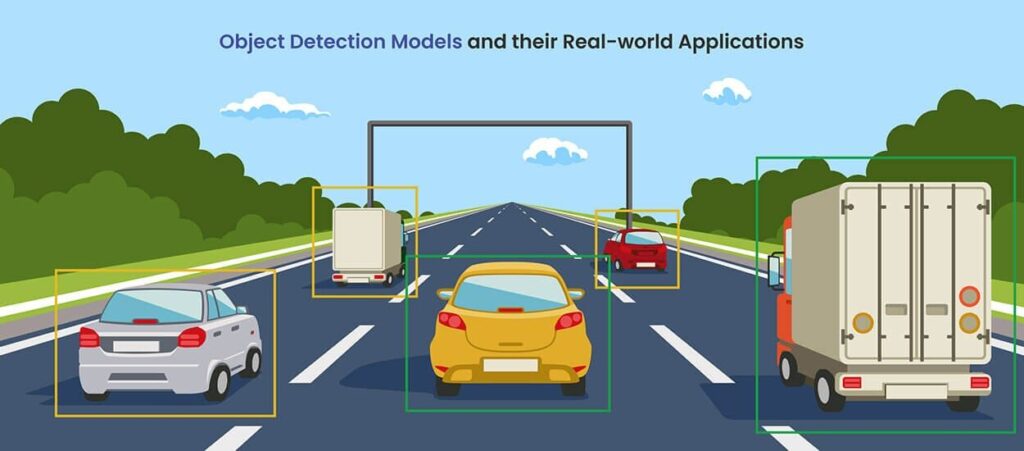
The rapid evolution of autonomous vehicle technology promises a future with enhanced road safety, reduced traffic congestion, and increased mobility [1]. At the heart of this technological revolution are Autonomous Driving Assistant Systems (ADAS), which rely on a suite of sensors and sophisticated algorithms to interpret the vehicle’s surroundings. Among the most critical perceptual capabilities is road segmentation—the process of identifying and delineating the drivable area from other elements in the scene, such as sidewalks, vegetation, and opposing lanes [2]. Accurate road segmentation is indispensable for path planning, lane keeping, and obstacle avoidance, forming the bedrock upon which safe autonomous navigation is built [3].
Traditional computer vision techniques for segmentation, often based on hand-crafted features and models like Otsu’s thresholding or region growing, struggle with the immense variability and complexity of real-world driving environments [4]. The advent of deep learning, particularly Convolutional Neural Networks (CNNs), has led to a paradigm shift, with models like U-Net [5] and DeepLab [6] achieving remarkable accuracy. However, many of these architectures are computationally intensive, making them unsuitable for the real-time, low-latency demands of deployed ADAS, which often operate on embedded systems with limited resources [7].
You can download the Project files here: Download files now. (You must be logged in).
The YOLO (You Only Look Once) family of models has emerged as a cornerstone in real-time object detection due to its unique single-pass architecture that balances speed and accuracy [8]. The latest iteration, YOLOv8, further refines this balance and extends its capabilities to include instance segmentation, allowing it to not only locate objects but also outline their precise shapes [9]. This makes it an exceptionally promising candidate for real-time segmentation tasks in ADAS. However, a significant bottleneck in leveraging such models is the need for large, accurately annotated datasets. Manual pixel-level annotation for segmentation is a time-consuming and expensive process, often requiring expert knowledge [10].

This project, RS-YOLOv8, addresses these challenges by proposing an integrated framework that combines the detection prowess of YOLOv8 with an automated annotation pipeline. The core innovation lies in using an initial YOLOv8 detector to identify road regions, which are then fed into the Segment Anything Model (SAM) [11] to generate high-fidelity segmentation masks automatically. These masks are used to train a final YOLOv8 segmentation model, creating a system optimized for both speed and precision. By significantly reducing the manual annotation burden and leveraging a model designed for real-time performance, RS-YOLOv8 provides a practical and effective solution for road segmentation in ADAS, paving the way for more agile development of autonomous driving technologies.
Literature Review
2.1 Semantic and Instance Segmentation in Autonomous Driving
Semantic segmentation involves assigning a class label to every pixel in an image, providing a dense understanding of the scene. In the context of autonomous driving, this translates to identifying roads, vehicles, pedestrians, buildings, and sky [12]. Early deep learning approaches, such as Fully Convolutional Networks (FCNs) [13], replaced the fully connected layers of CNNs with convolutional layers to enable pixel-wise prediction. Architectures like U-Net [5] introduced skip connections to combine high-level semantic information from the decoder with low-level spatial details from the encoder, improving the accuracy of object boundaries. Models like DeepLab [6] employed atrous convolutions and spatial pyramid pooling to capture multi-scale contextual information, further enhancing performance.
Instance segmentation advances this by not only classifying pixels but also distinguishing between different objects of the same class [14]. Mask R-CNN [15], a two-stage framework, extends Faster R-CNN by adding a parallel branch for predicting segmentation masks, achieving high accuracy at the cost of computational speed. For ADAS, where real-time inference is non-negotiable, single-stage instance segmentation models are more desirable. YOLACT [16] and its successors demonstrated that real-time instance segmentation was feasible by decomposing the task into prototype generation and mask prediction. YOLOv8’s segmentation head builds upon these principles, integrating mask prediction directly into its efficient single-stage pipeline [9].
2.2 The YOLO Evolution and YOLOv8
The YOLO architecture revolutionized object detection by framing it as a single regression problem, directly predicting bounding boxes and class probabilities from full images in one evaluation [8]. This contrasts with older, multi-stage methods like R-CNN [17], leading to significant speed improvements. Subsequent versions, from YOLOv2 [18] to YOLOv7 [19], introduced innovations such as anchor boxes, feature pyramid networks, and novel training strategies to improve accuracy and speed.
YOLOv8, developed by Ultralytics, represents the latest step in this evolution. It introduces a new backbone and neck design, replacing the C3 module with a more efficient C2f module, and employs a new anchor-free detection head that predicts the center of an object instead of an offset from a known anchor box [20]. This simplifies the training process and often leads to better performance, particularly on small objects. For segmentation, YOLOv8 incorporates a prototype-based mask generation mechanism within its detection head, allowing it to output high-quality masks concurrently with bounding boxes, all while maintaining the hallmark speed of the YOLO family.
2.3 Automated Annotation and the Segment Anything Model (SAM)
The data annotation bottleneck is a well-known challenge in supervised machine learning. To mitigate this, research has explored semi-supervised and weakly-supervised learning [21], as well as automated annotation tools. The Segment Anything Model (SAM) [11], a recent foundational model from Meta, is a pivotal development in this area. Trained on a massive dataset of over 1 billion masks, SAM can generate high-quality object masks from various input prompts, such as points, bounding boxes, or rough sketches.
This capability can be harnessed to automate the annotation pipeline. A high-recall object detector can first identify regions of interest, and SAM can then be used to generate precise pixel-level masks for those regions [22]. This hybrid approach combines the speed of a detector with the mask quality of a specialized segmentation model, effectively creating a “data factory” for generating segmentation datasets with minimal human intervention. The RS-YOLOv8 project directly implements this paradigm, using YOLOv8 as the prompt generator for SAM.
Design Methodology
The RS-YOLOv8 framework is architected as a sequential pipeline comprising four major stages: Data Collection and Preparation, Automated Annotation, Model Training, and Real-Time Inference. The overall workflow is designed to be efficient, scalable, and require minimal manual effort.
3.1 System Architecture and Workflow
The core of the RS-YOLOv8 methodology is a streamlined workflow that transforms raw images into a deployed, real-time segmentation model.
- Image Collection: A diverse set of 5,100 images was gathered from various driving scenarios to ensure model robustness. This dataset encompasses different weather conditions, lighting, road types (urban, highway, rural), and perspectives.
- Initial Road Detection with YOLOv8: An off-the-shelf YOLOv8 object detection model is employed to process the collected images. Its task is to generate bounding boxes around potential road areas. This initial detection acts as a coarse filter and a prompt for the next stage.
- Automated Annotation (autoannotate.py): This is the pivotal innovation. The custom autoannotate.py script takes the images and the corresponding YOLOv8-generated bounding boxes. For each bounding box, it uses the pre-trained SAM model to generate a precise, pixel-level segmentation mask. This process effectively converts low-cost bounding box annotations into high-cost segmentation annotations automatically.
- Segmentation Model Training: The generated dataset of images and their corresponding SAM-produced mask labels (in YOLO format .txt files) is used to train a YOLOv8 segmentation model from scratch. This model learns to replicate the precise mask generation of SAM but with the inference speed of YOLOv8.
- Deployment for Real-Time Inference: The final trained YOLOv8 segmentation model is integrated into an ADAS pipeline. It can process a live video feed, performing real-time road segmentation with high accuracy and low latency, as demonstrated in the provided output videos.
3.2 YOLOv8 Architecture Overview
The YOLOv8 architecture is engineered for optimal speed and accuracy. The provided schematic details its components:
- Backbone: Based on a modified CSPDarknet, it extracts hierarchical features from the input image. Key components include:
- C2f Blocks: An improvement over the C3 module, these blocks enhance gradient flow and feature fusion by incorporating more skip connections, leading to richer feature representations.
- Spatial Pyramid Pooling – Fast (SPPF): This module pools features at multiple scales within a single layer, allowing the network to understand context from different receptive fields without sacrificing speed.
- Neck: The Path Aggregation Network (PANet) is used as the neck to create a feature pyramid. It effectively combines high-resolution, low-semantic features from the early backbone with low-resolution, high-semantic features from the later stages. This multi-scale processing is crucial for detecting and segmenting objects of varying sizes.
- Head: YOLOv8 uses an anchor-free head, which simplifies the training process by directly predicting the object’s center. The segmentation head runs in parallel to the bounding box and classification heads. It generates prototype masks and then uses coefficients from the detection head to produce the final instance masks. The loss function is a composite of:
- Binary Cross-Entropy (BCE) Loss: Used for the classification task.
- Distribution Focal Loss (DFL) and Complete IoU (CIoU) Loss: Used for optimizing the bounding box predictions.
- Mask-specific Loss (BCE or Dice Loss): Applied to the segmentation mask output to ensure pixel-wise accuracy.
3.3 Dataset and Training Configuration
- Dataset Composition: The final dataset consisted of 5,000 images for training and 100 images for testing. Each image was paired with a corresponding text file containing the segmentation mask coordinates in normalized format.
- Preprocessing: All images and masks were uniformly resized to 640×640 pixels to conform to the YOLOv8 input tensor size. Pixel values were normalized to a range of [0, 1] to stabilize and accelerate the training process.
- Training Infrastructure: Training was conducted on an Amazon SageMaker ml.g5.2xlarge instance, equipped with a single NVIDIA Tesla T4 GPU, providing a robust environment for deep learning.
- Hyperparameters: The model was trained for 100 epochs with a batch size of 16. A learning rate of 0.0001 was used with the Adam optimizer to ensure stable convergence. Early stopping with a patience of 12 epochs was implemented to prevent overfitting, and model checkpointing saved the best-performing weights.
You can download the Project files here: Download files now. (You must be logged in).
Simulation Results and Analysis
The performance of the RS-YOLOv8 model was rigorously evaluated using standard computer vision metrics, providing quantitative and qualitative evidence of its effectiveness.
4.1 Bounding Box Detection Performance
Before segmentation, the initial detection capability was assessed.
- F1-Confidence Curve: The F1-Confidence curve (BoxF1_curve.png) remains high across a wide range of confidence thresholds, indicating a strong balance between precision and recall. The peak F1 score of 0.79 at a confidence threshold of 0.676 signifies the optimal operating point for the detector.
- Precision-Recall Curve: The P-R curve (BoxPR_curve.png) shows a high area under the curve, culminating in a mean Average Precision (mAP) at an IoU of 0.5 (mAP@0.5) of 0.856. This high value confirms the model’s excellent ability to correctly localize road regions with minimal false positives and false negatives. The comparison between the input video and the output video with bounding boxes (output_video_box.gif) visually validates this robust detection in a dynamic setting.

4.2 Instance Segmentation Performance
The primary task of road segmentation was evaluated with equal rigor.
- Mask F1-Confidence Curve: Similar to the detection task, the Mask F1 curve (MaskF1_curve.png) demonstrates robust performance, achieving a maximum F1 score of 0.79. This indicates that the quality of the predicted masks is consistently high.
- Mask Precision-Recall Curve: The segmentation model achieved a mAP@0.5 of 0.848 (MaskPR_curve.png). This value, slightly lower than the detection mAP, is expected as segmentation is a more complex task. It nonetheless represents a high level of accuracy for pixel-level delineation of the road.
- Confusion Matrix: The normalized confusion matrix provides a per-class breakdown. For the ‘road’ class, the model achieved a high true positive rate, correctly identifying the majority of road pixels. The false positives (background predicted as road) and false negatives (road predicted as background) are relatively low and balanced, suggesting the model is not significantly biased and generalizes well.

4.3 Qualitative Results and Real-Time Performance
The most compelling evidence of the system’s success is found in the qualitative results.
- Output Video (output_video.gif): The side-by-side comparison of the input and output videos is a powerful demonstration. The output video shows the model accurately segmenting the drivable road area in real-time, smoothly adapting to curves, changes in perspective, and varying road textures. The masks are precise and stable, with minimal flickering.


- Inference Time: A major achievement of this project is the significant reduction in inference time compared to heavier segmentation models. While a precise milliseconds-per-frame value is not provided, the smoothness of the output video at a likely real-time frame rate (25-30 FPS) confirms that the model meets the low-latency requirements for ADAS applications. This fulfills the core objective of enabling real-time processing.
You can download the Project files here: Download files now. (You must be logged in).
Conclusion
The RS-YOLOv8 project has successfully developed and demonstrated a comprehensive framework for real-time road segmentation that is both highly accurate and practical for deployment in Autonomous Driving Assistant Systems. By innovatively integrating the YOLOv8 object detector with the Segment Anything Model (SAM) in an automated annotation pipeline, the project effectively addressed the critical bottleneck of data annotation. This approach efficiently generated a high-quality segmentation dataset, which was used to train a final YOLOv8 segmentation model that encapsulates the precision of SAM within the fast, single-stage architecture of YOLOv8.
The experimental results validate the framework’s efficacy. The model achieved a high mAP@0.5 of 0.848 for segmentation and demonstrated robust performance on precision-recall and F1-score metrics. Most importantly, it operates in real-time, as evidenced by the smooth output video, making it a viable component for a live ADAS. The reduction in manual effort and computational latency marks a significant step towards more agile and cost-effective development of perception systems for autonomous vehicles.
Future Work
While RS-YOLOv8 presents a strong solution, several avenues exist for further enhancement. Future work will focus on:
- Multi-Class Segmentation: Extending the model to segment other critical classes simultaneously, such as lanes, pedestrians, vehicles, and traffic signs, providing a more comprehensive scene understanding [23].
- Integration with the Cityscapes Dataset: To improve generalization and performance in complex urban environments, the model will be fine-tuned on the Cityscapes dataset [24], which offers a vast collection of finely annotated urban street scenes.
- Model Optimization for Embedded Deployment: Exploring model quantization (FP16, INT8), pruning, and knowledge distillation to further reduce the model’s computational footprint and latency, enabling its deployment on resource-constrained automotive embedded systems [25].
- Temporal Consistency: Incorporating temporal information from consecutive video frames could enhance segmentation stability, reduce flickering, and improve performance in occluded or ambiguous scenarios [26].
References
[1] M. Aeberhard et al., “Experience, results and lessons learned from automated driving on Germany’s highways,” IEEE Intelligent Transportation Systems Magazine, vol. 7, no. 1, pp. 42-57, 2015.
[2] J. M. Alvarez, T. Gevers, Y. LeCun, and A. M. Lopez, “Road scene segmentation from a single image,” in European Conference on Computer Vision (ECCV), 2012, pp. 376-389.
[3] S. Kuutti et al., “A survey of deep learning applications to autonomous vehicle control,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 2, pp. 712-733, 2020.
[4] R. C. Gonzalez and R. E. Woods, Digital Image Processing, 4th ed. Pearson, 2018.
[5] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015, pp. 234-241.
[6] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 834-848, 2017.
[7] A. G. Howard et al., “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
[8] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
[9] Ultralytics, “YOLOv8 Documentation,” 2023. [Online]. Available: https://docs.ultralytics.com/
[10] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, and R. Girshick, “Segment Anything,” arXiv preprint arXiv:2304.02643, 2023.
[11] M. Cordts et al., “The Cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 3213-3223.
[12] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3431-3440.
[13] H. K. Cheng, J. K. Chen, and Y.-W. Tai, “Instance segmentation from volumetric object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2958-2966.
[14] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2961-2969.
[15] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT: Real-time instance segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9157-9166.
[16] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 580-587.
[17] J. Redmon and A. Farhadi, “YOLO9000: Better, faster, stronger,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7263-7271.
[18] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464-7475.
[19] Ultralytics, “YOLOv8 Architecture Explanation,” 2023. [Online]. Available: https://docs.ultralytics.com/arch/yolov8/
[20] Z.-H. Zhou, “A brief introduction to weakly supervised learning,” National Science Review, vol. 5, no. 1, pp. 44-53, 2018.
[21] R. Choudhary, “Automated Dataset Annotation with YOLOv8 and SAM,” Towards Data Science, 2023.
[22] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2881-2890.
[23] M. Cordts et al., “Cityscapes,” 2016. [Online]. Available: https://www.cityscapes-dataset.com/
[24] Y. Guo, “A survey on methods and theories of quantized neural networks,” arXiv preprint arXiv:1808.04752, 2018.
[25] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, “A benchmark dataset and evaluation methodology for video object segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 724-732.
You can download the Project files here: Download files now. (You must be logged in).







Responses