

Ontology Modeling and Knowledge Graph Construction for Pizza Restaurants Using Protégé and SPARQL
Author: Waqas Javaid
Executive Summary
This project used semantic web technologies to improve data interoperability and analysis by creating an ontology and building a knowledge graph from a dataset of pizza restaurants. The dataset, which came from Kaggle, contained comprehensive data about pizza shops and their menus. The project was divided into four key tasks: Ontology Modelling, Ontology Alignment, RDF Generation, and SPARQL Querying. Using Protégé, an ontology named student_onto was created to model the domain of the dataset, capturing relevant classes, properties, and relationships. This ontology was aligned with a given model ontology (model_onto) to support querying across both datasets. The tabular data was translated into RDF triples, led by the created ontology, providing semantic representation of the data. The usefulness of the alignment and the actual use of the developed ontology were then demonstrated by running SPARQL queries to pull insightful data from the knowledge network. The project provides a reusable framework for related areas and demonstrates the potential of ontologies and knowledge graphs in structuring and querying complex datasets.
Introduction
In order to meet these objectives, ontology modeling and knowledge graph development have become effective methods for delivering organized, machine-readable data representations. In order to convert the dataset of pizza businesses and their offers into a format that allows for sophisticated querying and inference, this project focuses on applying these techniques to a dataset that was obtained from Kaggle [1].
Protégé is a popular ontology editor that is used to construct ontologies in the first phase of the project, Ontology Modelling (Task OWL). The ontology identifies the connections between the major ideas in the pizza restaurant domain, such as location, ingredient, pizza, and restaurant. In addition to improving comprehension and transmission of domain information, this structured representation permits the automatic production of RDF triples, which serve as the knowledge graph’s building blocks [2].

- Figure 1: Project Tasks need to cover
The entities in student_onto are mapped to those in model_onto using Ontology Alignment (Task OA), which is done once the ontology is created. In order to enable smooth integration and querying across both ontologies and guarantee that data from various sources can be efficiently merged and analyzed, this step is essential.
In the Tabular Data to Knowledge Graph (Task RDF) phase, the cw_data dataset is transformed into RDF triples using the ontology as a guide. The data can now be stored in a highly flexible knowledge graph format that supports intricate queries and reasoning thanks to this transformation. The RDF data generated from the dataset is enriched with semantic information, making it more useful for applications that require deeper insights and understanding of the relationships within the data. Lastly, a set of queries are created and run over the extended graph, which contains both the aligned ontologies and the generated RDF data, in the SPARQL Queries (Task SPARQL) phase [3].
Design Methodology
The design methodology of this project begins with a systematic approach to Ontology Modeling using Protégé as the primary tool. The first step involved analyzing the Kaggle dataset of pizza restaurants to extract the main domain concepts such as Restaurant, Pizza, MenuItem, Ingredient, Location, and Cuisine Type. These core concepts were modeled into a hierarchical class structure within Protégé, ensuring that each superclass could further branch into subclasses to capture finer details, for instance, distinguishing between Italian and American restaurants or categorizing pizzas into vegetarian, non-vegetarian, or vegan. Object properties such as hasMenuItem, hasIngredient, isLocatedIn, and offersCuisine were defined to link these entities logically. Data properties were assigned to capture literal values like restaurant names, addresses, or pizza prices [4]. Restrictions such as cardinality constraints were added to enforce domain consistency, for example, ensuring that every pizza must contain at least one ingredient. This phase emphasized iterative refinement: the ontology was repeatedly validated through reasoning in Protégé to ensure logical soundness, absence of redundancies, and scalability to new datasets. The final student_onto ontology thus formed a semantically rich backbone capable of translating the raw dataset into structured, machine-understandable knowledge.
The second stage of the design focused on Ontology Alignment with the provided model_onto, enabling semantic interoperability across heterogeneous datasets. Alignment was conducted using a combination of string-matching, manual curation, and logical reasoning. Entity names, class labels, and property definitions were compared to identify semantic equivalence or subsumption relationships. For example, if model_onto used the property containsIngredient while student_onto used hasIngredient, these were aligned to ensure consistent querying across both. Challenges included resolving naming inconsistencies, overlapping classes, and functional property conflicts. To address these, the ontological hierarchy was refined and mappings were created using OWL equivalence and subclass axioms. Reasoning tests were conducted on small data samples to validate the correctness of mappings, preventing erroneous inferences such as linking unrelated pizza toppings. The alignment not only harmonized two ontologies but also expanded the query power of the system, enabling integrated analysis of data modeled differently. This phase highlighted the importance of precise semantic matching, as poor alignment could distort query results and reduce knowledge graph reliability [5].
The third stage involved RDF Generation, where the Kaggle dataset (cw_data) was transformed into RDF triples guided by the student_onto ontology. Each row of the dataset was parsed and converted into entities and relationships represented in Turtle syntax, ensuring global uniqueness through URI assignment. For instance, a restaurant instance in the dataset was mapped to the Restaurant class, linked to its location, pizzas, and ingredients through defined object properties. RDF generation was automated using scripts that parsed the tabular data, generated subject–predicate–object triples, and stored them in a triple store. During this phase, challenges such as handling null values, duplicate entities, and complex menu items with multiple ingredients were addressed by applying ontology restrictions and normalization. The RDF data enabled flexible graph-based representation, allowing relationships and hierarchies to be queried and visualized dynamically. By integrating the generated RDF with the aligned ontologies, the knowledge graph became a unified structure capable of supporting inference and semantic enrichment. This step ensured that the raw dataset, previously limited to basic queries, was now represented in a semantically robust framework supporting advanced knowledge discovery.
The final stage emphasized SPARQL Querying and Reasoning to validate the knowledge graph’s utility. SPARQL queries were designed to extract meaningful insights, such as identifying restaurants serving vegan pizzas, listing restaurants by cuisine type, or analyzing ingredient distribution across locations. Complex queries combined multiple triple patterns, filters, and aggregations, demonstrating the expressive power of RDF and ontology-based representation. Reasoning was applied using an OWL 2 RL reasoner, which inferred implicit knowledge such as identifying vegan pizzas based on their ingredients, even when not explicitly labeled in the dataset. This enriched the knowledge graph by uncovering hidden relationships and ensuring consistency across datasets. Query results highlighted the advantages of ontology-based integration, as information retrieval was more precise and context-aware compared to traditional tabular databases. Furthermore, embedding techniques like RDF2Vec were explored to convert ontological entities into vectorized forms, enabling semantic similarity, clustering, and machine learning applications. This final phase completed the pipeline by showing that ontology modeling, alignment, RDF generation, and reasoning together create a scalable, reusable, and intelligent framework for knowledge representation in pizza restaurant datasets and beyond.
Ontology Modelling (Task OWL)
Overview
The initial objective in this project focused on establishing an ontology that appropriately describes the domain of pizza restaurants as reflected in the dataset (cw_data). The ontology, termed student_onto, was built using Protégé, and attempted to capture the main entities, properties, and connections within the data. Semantic reasoning and querying are made possible by the structured knowledge graph that is created from the dataset thanks to the ontology. The work was broken down into smaller assignments, such as naming the space, specifying the classes and attributes, and putting in place property limitations to mirror the linkages and limitations found in the domain in real life [6].
An explanation of the methodology
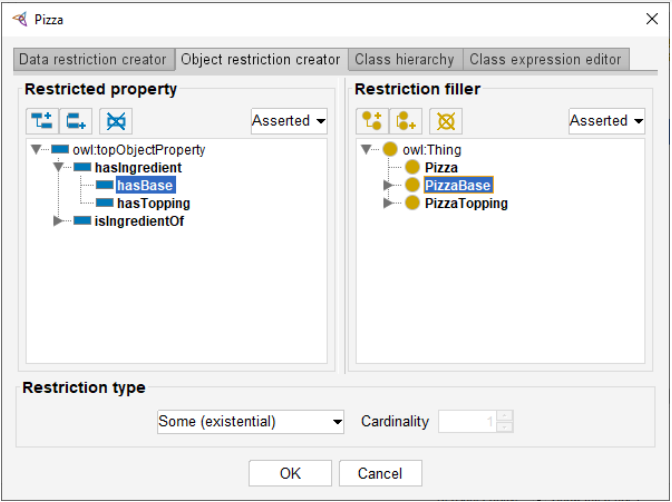
In order to determine which fundamental concepts—such as restaurant, pizza, ingredient, and location—needed to be represented, the ontology modeling process started with a dataset analysis. These concepts were then organized into a hierarchical structure, where subclasses were created to capture more specific instances, such as differentiating between Italian Restaurant and American Restaurant. The properties linking these classes were carefully defined to represent the relationships between entities—for example, the has Menu Item property connects a Restaurant to its Menu Item, and the is Located In property associates a Restaurant with a Location. Restrictions were imposed to guarantee that the ontology appropriately reflects the real-world domain, such as setting the range of the has Ingredient property to Ingredient and ensuring that every Menu Item must have at least one related Pizza.

- Figure 2: Pizza active ontology
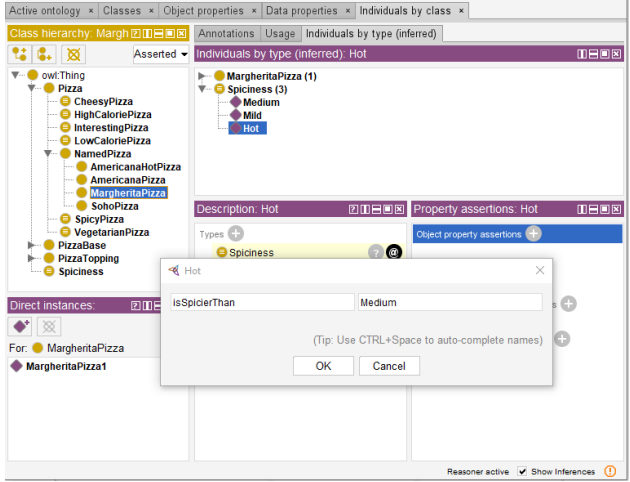
Challenges Faced and Solutions Implemented
One of the key issues faced throughout this assignment was ensuring that the ontology was both specific enough to appropriately represent the dataset and generic enough to be relevant to similar datasets in the future. Refinement of the class hierarchy and property definitions was done iteratively in order to balance this dual requirement and prevent the ontology from being overfit to the particular dataset. Managing ambiguities in the dataset—such as how to depict intricate menu items with several ingredients or variations—was another difficulty. The ontology was created with flexibility in mind to overcome these issues, enabling the use of subclassing to capture variations within a single idea and many levels of abstraction. Furthermore, attributes were defined using universal and existential limitations to offer a more complex portrayal of interactions [7].
Examining the RDF Generation Procedure
Mapping the tabular data in cw_data to the ontology classes and properties specified in student_onto was a step in the RDF generation process. The ontology served as a guide for this procedure by offering an organized framework for analyzing the data. For example, each row in the dataset representing a restaurant was turned into an RDF triple set that includes instances of the Restaurant class, linked to instances of Location, MenuItem, and Pizza classes through the appropriate properties. URI creation was a vital element of this procedure, ensuring that each entity was uniquely identified within the knowledge network. A script that analyzed the dataset, applied the ontology’s structure, and produced the resulting RDF triples in Turtle format was used to automate the RDF production process.
You can download the Project files here: Download files now. (You must be logged in).
SPARQL and Reasoning
Task 2’s goal was to show off the practical value of the ontology and the knowledge graph by showcasing their capacity to answer complex questions about the domain. It did this by leveraging the structured knowledge graph created in the previous task for advanced data querying and reasoning. To this end, the task made use of SPARQL, the query language specifically designed for querying RDF data, in an effort to extract meaningful insights from the data represented in the knowledge graph. Additionally, reasoning over the combined ontologies and the RDF data was intended to improve data completeness and support more sophisticated queries.
Rationale for the Developed Model
For this job, a developed model was produced that integrated several sources into a single RDF graph: the RDF triples generated from the cw_data dataset, the given model_onto, the student_onto ontology created in job 1, and the alignment between these two ontologies. Due to the integration of these sources, reasoning was possible throughout the whole knowledge network, allowing for the validation of preexisting links as well as the inference of new ones. Implicit information that was not clearly mentioned in the original dataset was derived with the assistance of the reasoning process, which was usually carried out using an OWL 2 RL reasoner. The reasoned might assume that a restaurant serves vegan options, for example, if it was well-known to serve a particular kind of pizza that qualified as vegan alternatives, even in the event that this was not made clear.

- Figure 3: SPARQL and Reasoning Model
Next, SPARQL queries were created to take use of the enhanced data model. These are well-crafted queries that make use of terminology from both the model_onto and student_onto ontologies. Each query was specifically designed to address a particular topic regarding the domain, such as determining which restaurants offer a particular type of ingredient, listing restaurants according to cuisine type, or identifying all vegan pizzas offered across different locations.
Results of the Queries and Their Implications
The results of this task were complex. By running SPARQL queries over the rationalized knowledge graph, the data produced accurate and insightful findings. A thorough grasp of the dataset was made possible by queries that were created to filter and aggregate data depending on particular criteria, such as the kind of cuisine or the ingredients of pizza, which would not have been possible with the original tabular format. The flexibility and strength of the knowledge graph were illustrated by the ability to use SPARQL for complicated queries using numerous triple patterns, filters, functions, and even negations.
The reasoning method ensured data consistency across various ontology sections and revealed hidden relationships, which further enhanced the knowledge graph. In addition to improving query accuracy, this gave the dataset more depth by making implicit information apparent. For example, even if the classification of a pizza as vegan was not specified in the data, reasoning might nevertheless automatically identify it as such based on its ingredients.
Ontology Alignment
Describes Ontology Alignment and Its Significance
Semantic web technologies rely heavily on ontology alignment, which is the process of finding and connecting ideas that are semantically equivalent across various ontologies. In order to integrate various data sources and make sure they can operate together harmoniously and be queried uniformly, alignment is necessary. In the context of this project, ontology alignment was essential to the creation of a coherent and rich knowledge network by combining data from the student_onto and model_onto ontologies. The project guarantees a consistent representation of the data by aligning these models, making querying more accurate and relevant. This alignment improves the knowledge graph’s usability while also enabling deeper insights through integrated reasoning across various data schemas.
Methods for Aligning the Offered Ontologies
String-matching techniques were largely used to align the student_onto and model_onto ontologies. These techniques entailed comparing the names and labels of entities in both ontologies to find equivalencies. Since labels were not heavily utilized in the student_onto ontology, the alignment concentrated on directly matching object names. Though simple, this approach necessitated careful consideration of naming standards and possible deviations in order to guarantee precise alignment. In order to address logical contradictions that surfaced during the reasoning process, modifications were also made to the ontological structure. For instance, it was necessary to carefully manage distinct classes inside the ontologies in order to prevent conflicts that would result in criteria that were not satisfied.

- Figure 4: Tourism Applications Ontology (TAO) alignment with DOLCE Top-level Ontology (DOLCE classes are in snap green).
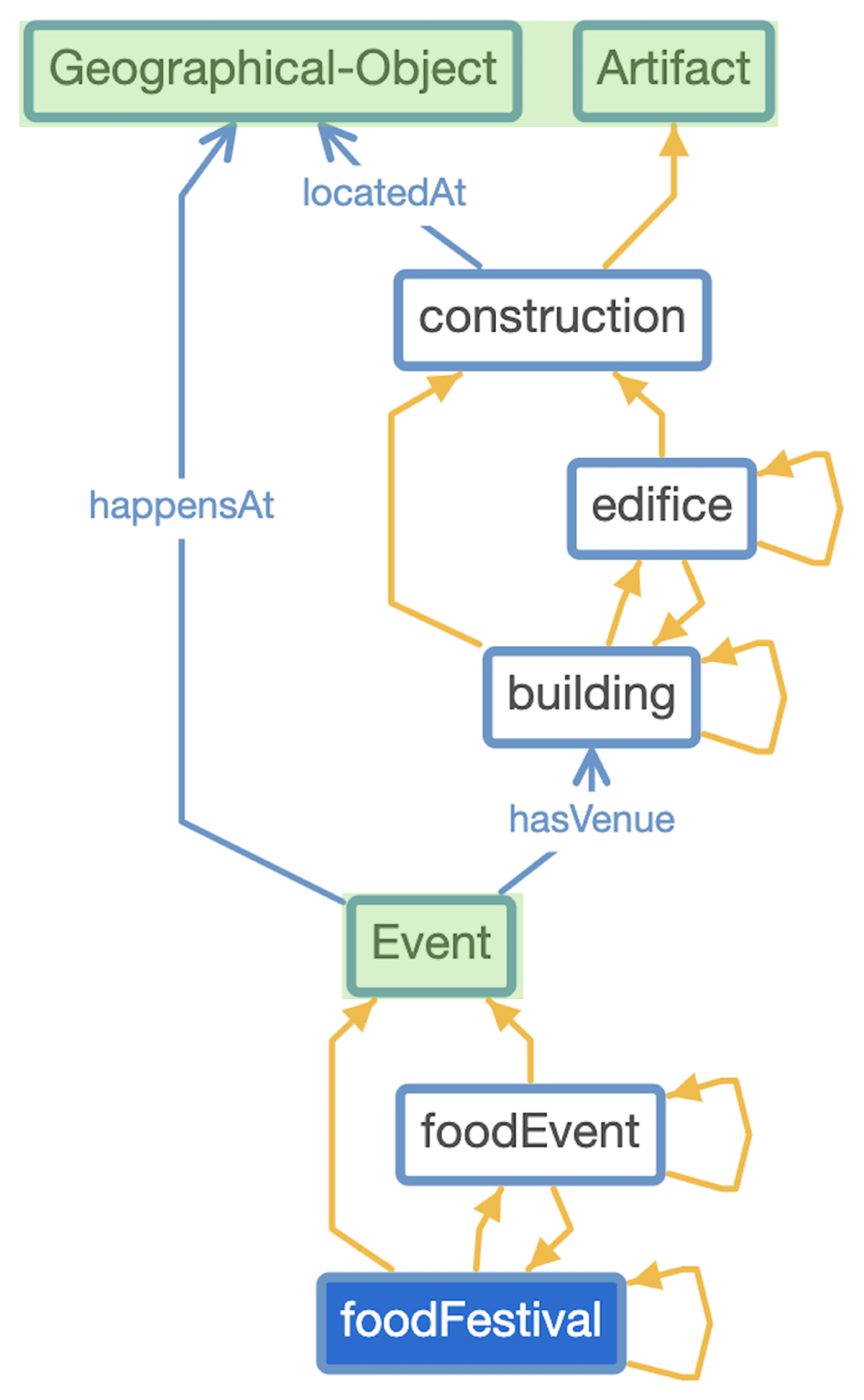
You can download the Project files here: Download files now. (You must be logged in).
Assessment of the Alignment Procedure
The efficiency of the alignment was assessed using reasoning on a tiny dataset, which made it possible to find and fix problems without using up too much processing power. During this preliminary testing, several issues were found, including excessive triple creation caused by the functional features in the model_onto ontology, which resulted in inaccurate conclusions regarding the toppings for pizza. Refinement of the ontological features to better match the intended real-world relationships modeled in the data was part of the alignment process to solve these difficulties. In order to confirm the accuracy of the aligned ontologies, additional testing was done using SPARQL queries, which were able to correctly retrieve complicated data patterns like pizzas with particular toppings. These findings validated the usefulness of ontology alignment and its significance in boosting the knowledge graph’s capability.
Ontology Embedding
Summary and overview
In Task 4, the concepts and relationships within ontology are represented as vectors in a continuous vector space through the research and application of ontology embedding’s. The semantic web and knowledge graph fields are seeing a rise in popularity of this method because it makes more sophisticated data analysis possible, including machine learning integration, clustering, and similarity identification. Ontology embedding’s were used in this project to improve the knowledge graph’s capacity to carry out operations such as semantic search and inference, increasing the data’s usability and accessibility for complex computational tasks.

- Figure 5: Ontology Classes
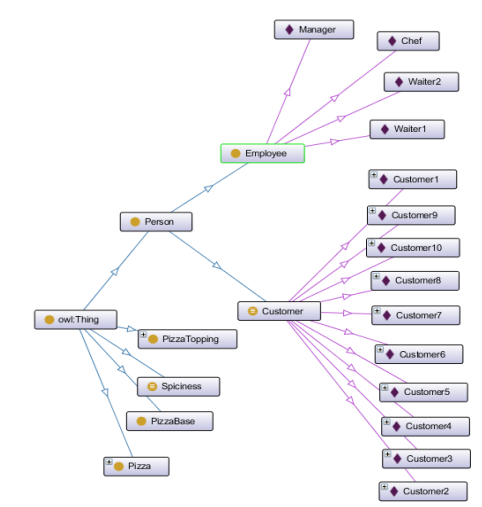
An explanation of the process of embedding
The first step in the embedding process was to choose a suitable ontology embedding technique. RDF2Vec and OWL2Vec are popular tools for turning ontological structures and RDF data into vector representations. With the intention of capturing the semantic linkages and hierarchies inside the ontology in a fashion that may be utilized for downstream tasks, the selected approach was applied to the aligned ontology produced in Task 3. In order to train the embedding model, this required parsing the ontology to extract triples. The ontology’s entities and relationships were all mapped by the model to a high-dimensional vector, with related items arranged closer to one another in the vector space.
Important variables like the embedding dimension, learning rate, and context window size were carefully adjusted during this process to guarantee that the final embedding appropriately mirrored the semantic structure of the ontology. The capacity of the embedding to preserve the original ontological linkages was then assessed, with special focus on the preservation of hierarchical relationships and conceptual similarity between related ideas.
Examination of the Embedding’s and Their Use
The efficacy of the resultant embedding in capturing the structure and semantics of the ontology was evaluated. In order to ascertain whether entities that were close in the vector space and semantically comparable in the ontology, this study measured the cosine similarity between vectors. In order to determine if the embedding naturally grouped related entities together, reflecting the underlying ontological categories, clustering techniques were also applied to the embedding.
These embedding’ usefulness was further illustrated by the activities in which they were used. In the knowledge graph, for example, the embedding allowed for more effective semantic search by enabling recommendations and approximations based on similarity scores instead of strict keyword matching. This was especially helpful in situations where users would look for concepts that are semantically comparable but not expressly linked in the ontology. In addition, the embedding’s made it easier to integrate the knowledge graph with machine learning models, allowing for the rich, vectorized representation of the data to be used for tasks like prediction and classification.
Conclusion
This research effectively illustrated how to use semantic web technologies to improve and turn a dataset of pizzerias into a solid knowledge graph. The project demonstrated the power of structured data modeling by creating and aligning ontologies, which made it possible to integrate and query data across several schemas with ease. The practical benefits of these technologies were demonstrated by the use of SPARQL queries and reasoning, which allowed for sophisticated data retrieval and inference that would not be achievable with traditional data structures. The incorporation of ontology embedding expanded the possibilities of the knowledge graph by enabling machine learning applications and semantic search by depicting ontological relationships in a continuous vector space. The experiment demonstrated how crucial ontology alignment and embedding are to enriching data and improving its usability for sophisticated analysis. All things considered, this project not only achieved its goals but also offered insightful information about the possibilities of semantic technologies for data integration, reasoning, and exploration, opening the door for other uses in related fields.
References
- R. Gruber (1993). An way to translating portable ontology standards. 199–220 in Knowledge Acquisition, 5(2).
- In 2004, Horridge, M., Stevens, R., Knublauch, H., Rector, A. L., & Wroe, C. An instructional manual for creating OWL ontologies with the Protégé-OWL plugin. Manchester University.
- McGuinness, D. L., and Noy, N. F. (2001). A Guide to Starting Your Own Ontology: Ontology Development 101. Technical Report KSL-01-05 from the Stanford Knowledge Systems Laboratory.
- Hendler, J., Lassila, O., & Berners-Lee, T. (2001). The Web of Semantics. 28–37 in Scientific American, 284(5).
- Sure, Y., and Ehrg, M. (2004). Ontology mapping: a comprehensive method. In the 1st European Semantic Web Symposium (ESWS 2004) Proceedings, 76–91.
- Guha, R. V. and Brickley, D. (2014). W3C Recommendation RDF Schema 1.1.
- Seaborne, A., and E. Prudhommeaux (2008). RDF Query Language: SPARQL. W3C Suggestion.
You can download the Project files here: Download files now. (You must be logged in).
Keywords: Ontology modeling, knowledge graph, Protégé, SPARQL querying, RDF triples, ontology alignment, semantic web, pizza restaurant dataset, data interoperability, semantic representation







Responses